We propose a novel evaluation task for video-text understanding, namely retrieval from counterfactually augmented data (RCAD), and a new Feint6K dataset, to better assess the capabilities of current video-text models and understand their limitations. To succeed on our new evaluation task, models must derive a comprehensive understanding of the video from cross-frame reasoning. Analyses show that previous video-text foundation models can be easily fooled by counterfactually augmented data and are far behind human-level performance. From our experiments on RCAD, we identify a key limitation of current contrastive approaches on video-text data and introduce LLM-teacher, a more effective approach to learn action semantics by leveraging knowledge obtained from a pretrained large language model.
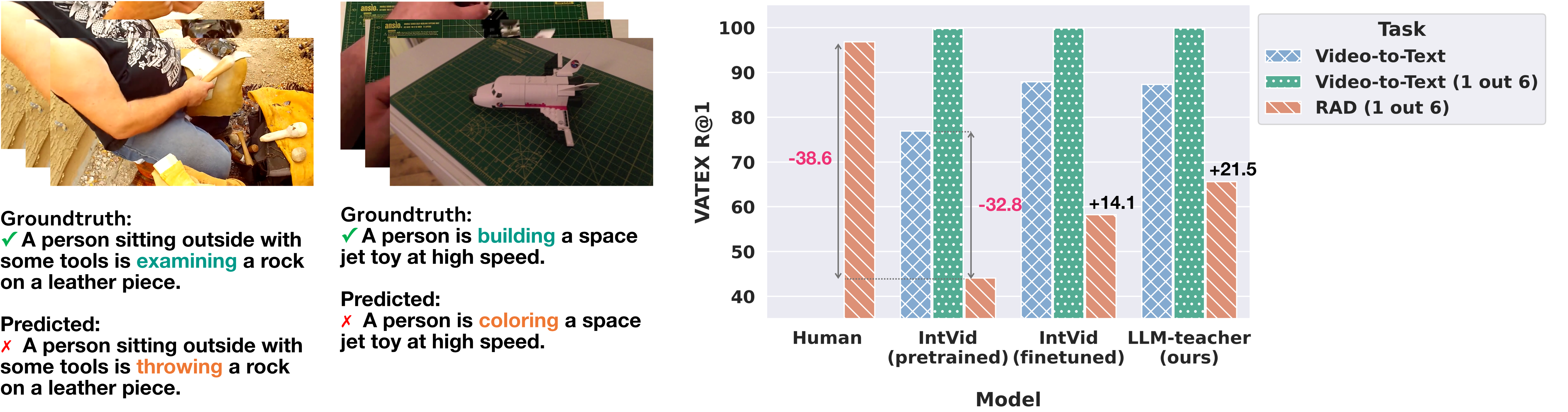
RCAD and Feint6K
Retrieval from counterfactually augmented data (RCAD) is a variant of the standard video-to-text retrieval. Given a video sequence and a list of candidate captions, the model needs to retrieve the caption that best matches the semantics in the video.
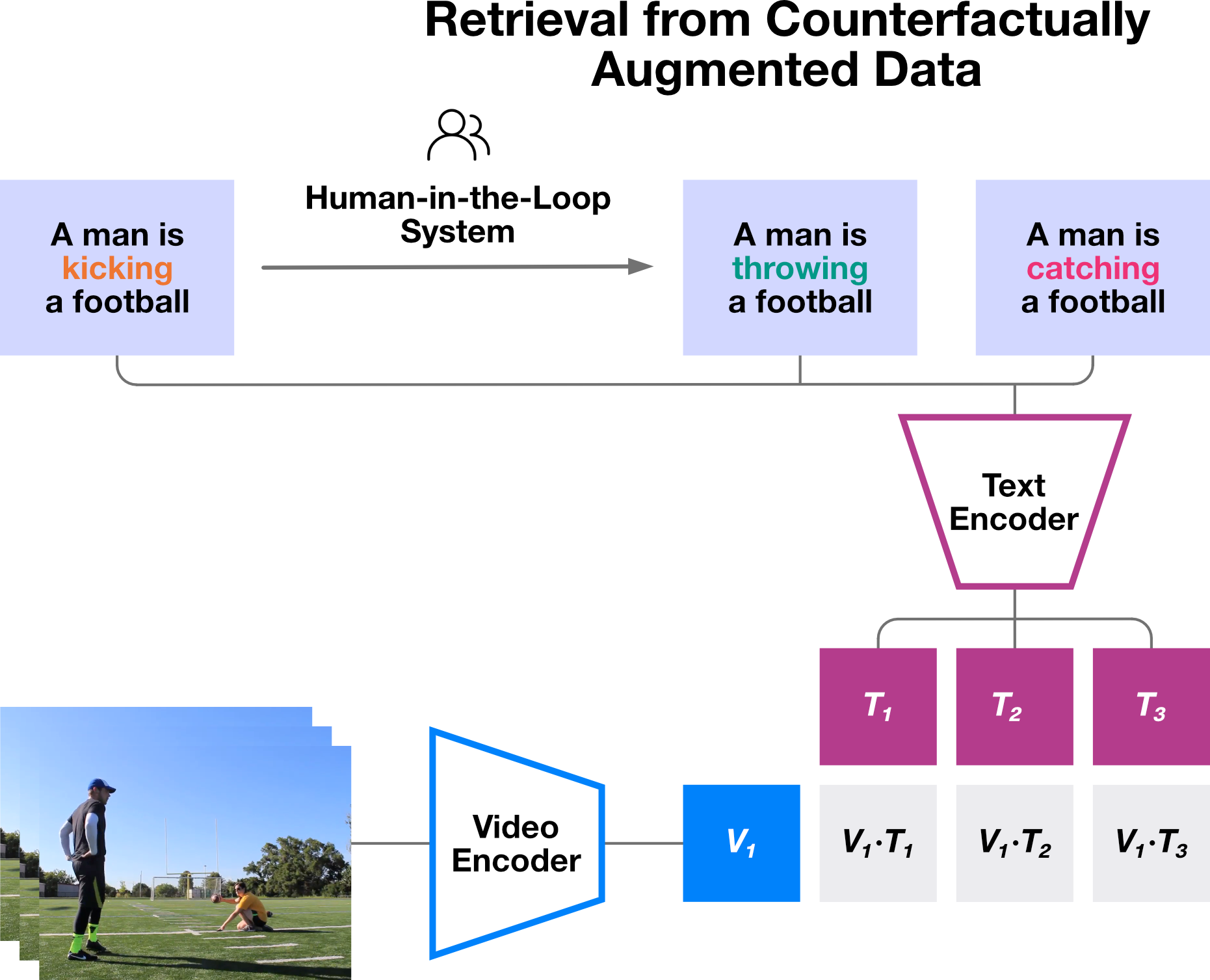
Our task features three key designs: (1) hard negative captions: unlike standard re-trieval tasks where negative captions come from other video-text pairs in the same dataset, negative captions in RCAD are modified from the positive captions, with the same text structure and object entities but different actions; (2) zero-shot evaluation: captions are manually modified from captions in existing datasets, offering the zero-shot evaluation of video-text foundation models; (3) challenging questions: cross-frame reasoning is necessary to obtain the correct answer since all candidate actions are plausible given the video's context.
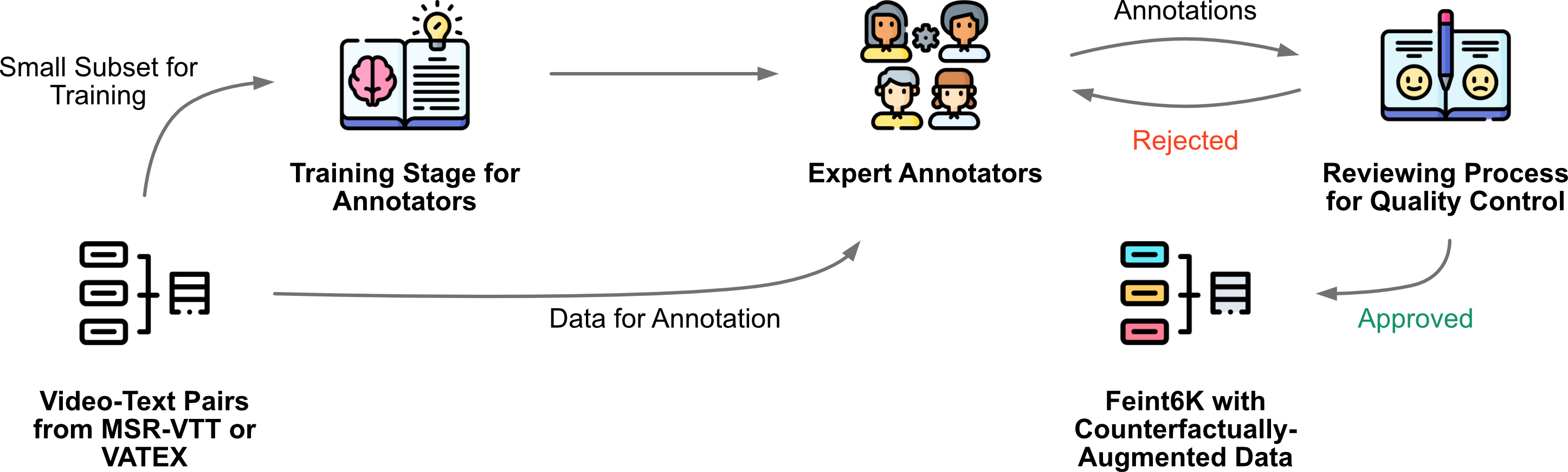
Data Collection of Feint6K
We adopt a human-in-the-loop system

Human Performance
We employ the same group of annotators to establish a human-level baseline on our Feint6K dataset. Analyzing the human performance serves two goals: (i) verifying the legitimacy of our Feint6K dataset -- if each question is answerable and has one unique answer, and (ii) comparing the state-of-the-art video-text models with human-level performance.
Key Findings
Previous SOTA video-text models demonstrate limited understanding of the action semantics in videos. Results in Table 1 show that previous video-text models achieve less than 60% R@1 accuray on RCAD, given a 16.7% R@1 accuray when taking random guesses. They also fall far behind human-level performance.
| Model | MSR-VTT | Feint6K (MSR-VTT) | VATEX | Feint6K (VATEX) | ||||
|---|---|---|---|---|---|---|---|---|
| R@1 | R@1 | R@3 | MeanR | R@1 | R@1 | R@3 | MeanR | |
| Human | 95.2 | 96.8 | ||||||
| Random | <1e-3 | 16.7 | <1e-3 | 16.7 | ||||
| Zero-shot | ||||||||
| CLIP |
26.3 | 37.3 | 55.3 | 2.6 | 38.8 | 34.8 | 54.3 | 2.7 |
| VideoCLIP |
14.5 | 35.1 | 71.3 | 2.6 | 13.7 | 33.0 | 70.7 | 2.7 |
| InternVideo |
37.5 | 45.8 | 63.6 | 2.3 | 76.9 | 44.1 | 63.9 | 2.3 |
| LanguageBind |
42.8 | 41.7 | 76.5 | 2.4 | 43.2 | 77.2 | 2.3 | |
| Finetuned | ||||||||
| CLIP4Clip |
43.1 | 50.8 | 72.4 | 2.0 | ||||
| VindLU |
46.6 | 53.4 | 70.9 | 2.0 | ||||
| SimVTP |
50.2 | 35.7 | 70.8 | 2.6 | 76.6 | 33.6 | 68.4 | 2.6 |
| InternVideo |
49.1 | 58.6 | 80.2 | 1.8 | 87.9 | 58.2 | 76.9 | 1.9 |
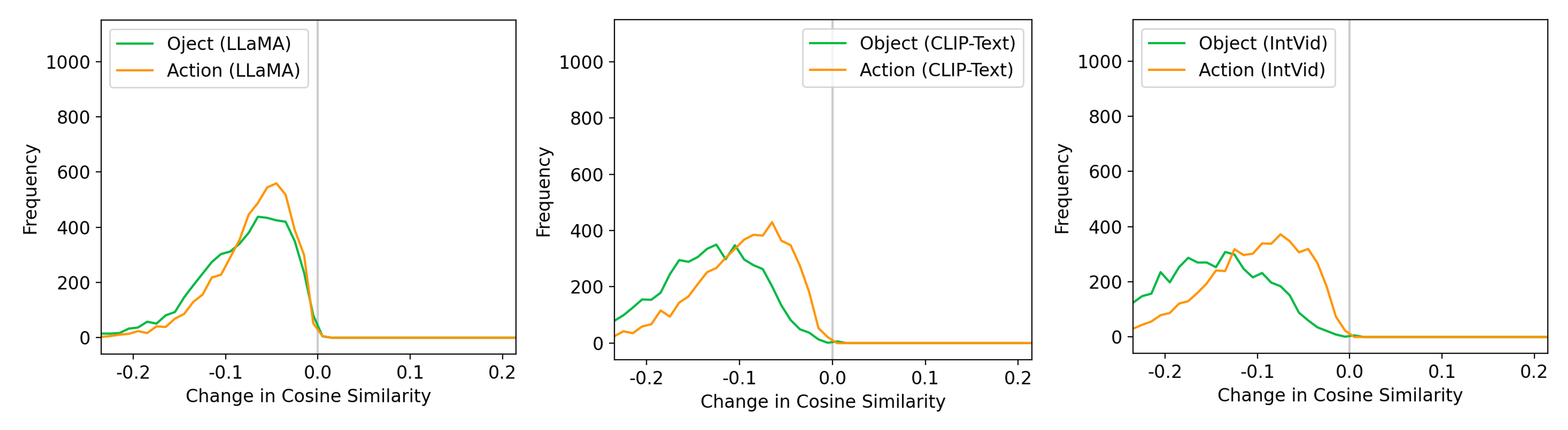
Current video-text models learn a more effective embedding for objects than for actions. With the counterfactually augmented data collected, we compute the change in cosine similarity between the textual and visual embeddings when the objects or actions in captions are swapped. In general the changes in cosine similarity should be negative and the models are more sensitive when the absolute values of the changes are larger. We observe that when actions are swapped, the changes in cosine similarity are sometimes positive and in general, less sensitive than when objects are manipulated.
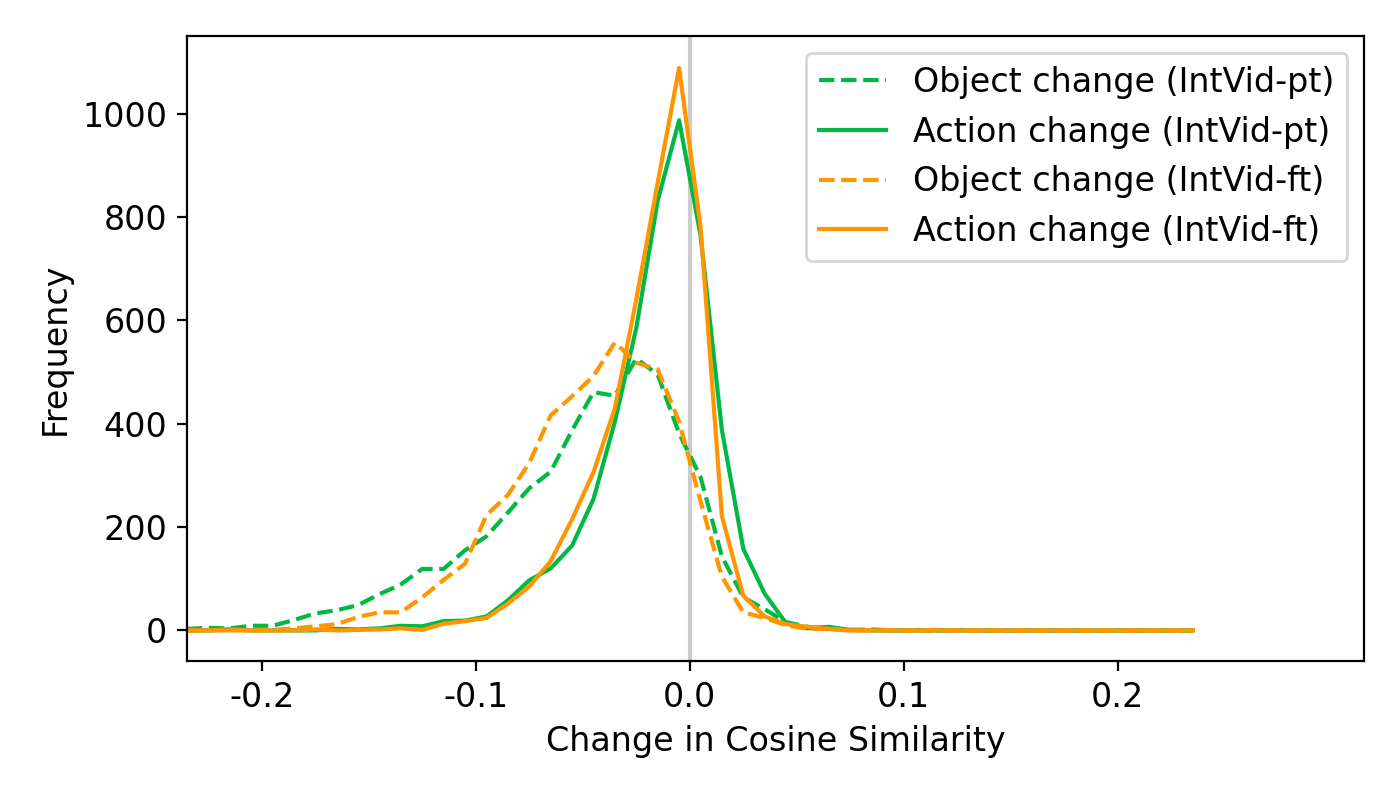
Shortcut learning in multi-modal contrastive pretraining. We also study the changes in cosine similarities between textual embeddings, using various textual encoders. We find that textual encoders trained with multi-modal contrastive learning are more sensitive to the changes in objects than to the changes in actions. This is not observed for textual encoders trained on texts only (such as LLaMA). We conjecture that objects act as shortcuts in multi-modal contrastive pretraining and hinder the model from learning an effective action representation.
LLM-Teacher
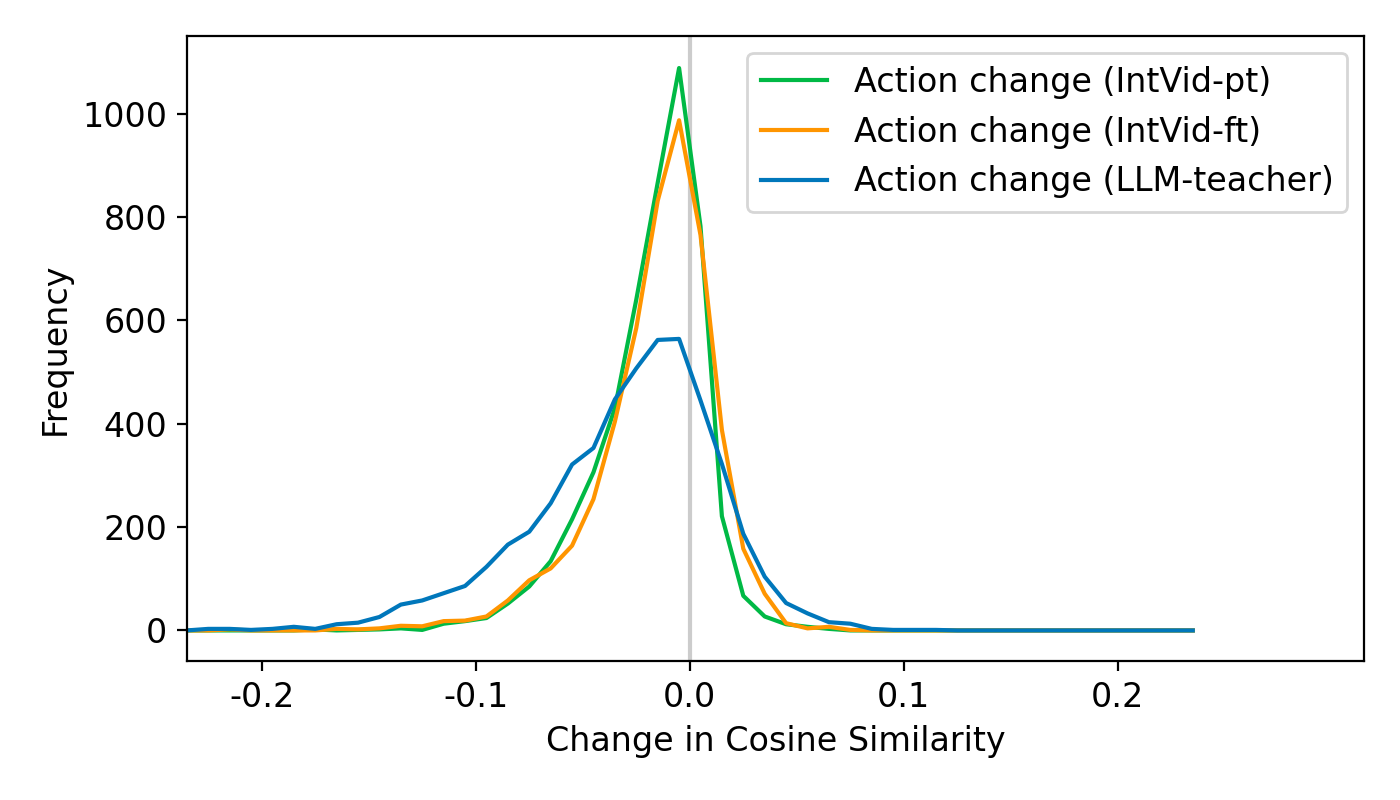
Given the observations above, we introduce LLM-teacher, an LLM-powered approach to better learn action representations with contrastive objectives. The idea is to remove shortcuts in paired video-text data for the model to learn action semantics more effectively. Specifically, LLM serves as the "teacher" and provide synthesized captions with pseudo-labels as extra knowledge for the model to learn from.
We first run an abstract meaning representation (AMR) parser and obtain a list of action and object tokens. Then we adopt (i) mask filling, or (ii) an LLM-powered chatbot to generate hard negative captions.
During training, LLM-teacher can either learn to retrieve the positive caption given the hard negative captions (i.e., LLM-teacher-lbl), or distill the cosiner similarities from a pretrained LLM model (i.e., LLM-teacher-lgt).
Results. Quantiative results show that LLM-teacher effectively improves the performance of RCAD on Feint6K. Moreover, results on changes in cosine similarity demontrate that LLM-teacher learns a more effective representation for action semantics in videos as compared to baseline models.
| Model | MSR-VTT | Feint6K (MSR-VTT) | VATEX | Feint6K (VATEX) | ||||
|---|---|---|---|---|---|---|---|---|
| R@1 | R@1 | R@3 | MeanR | R@1 | R@1 | R@3 | MeanR | |
| Finetuned | ||||||||
| InternVideo |
49.1 | 58.6 | 80.2 | 1.8 | 87.9 | 58.2 | 76.9 | 1.9 |
| w / LLM-teacher-lbl | 48.2 | 64.2 | 82.5 | 1.7 | 85.2 | 63.8 | 80.5 | 1.7 |
| w / LLM-teacher-lgt | 48.9 | 65.8 | 83.8 | 1.7 | 87.3 | 65.6 | 81.7 | 1.7 |
Miscellaneous
All data collection and experiments in this work were conducted at JHU.
License and agreement. By accessing and using our Feint6K dataset, you agree to follow the terms of access specified in our license file, our terms of use, and our privacy policy.
Ethics. We follow the ethics guidelines of ECCV and obtained Institutional Review Board (IRB) approvals prior to the start of our work. We described potential risks to the annotators, such as being exposed to inappropriate videos from public video datasets
BibTeX
@inproceedings{ma2024rethinking,
title={Rethinking Video-Text Understanding: Retrieval from Counterfactually Augmented Data},
author={Ma, Wufei and Li, Kai and Jiang, Zhongshi and Meshry, Moustafa and Liu, Qihao and Wang, Huiyu and H{\"a}ne, Christian and Yuille, Alan},
booktitle={European Conference on Computer Vision},
year={2024},
organization={Springer}
}
Copyright
Copyright © 2024 Meta Platforms, Inc.
Notes
This website template is adapted from Image Sculpting.